

Through the years, the usage of python for knowledge science has grown extremely and continues to develop day by day.
Information science is a big subject of examine with many sub-fields, of which knowledge analytics is undoubtedly one of the vital necessary of all these fields, and no matter one’s ability degree in knowledge science, it has grow to be more and more necessary to know or a minimum of have a fundamental understanding of it.
What’s Information Analytics?
Information analytics is the method of cleansing and remodeling a considerable amount of unstructured or disorganized knowledge, with the goal of producing necessary insights and details about this knowledge that may assist make knowledgeable selections.
There are numerous instruments used for knowledge evaluation, Python, Microsoft Excel, Tableau, SaS, and many others. However on this article, we’d give attention to how knowledge evaluation is finished in Python. Extra particularly, the way it’s finished with a python library referred to as Pandas.
What’s Pandas?
Pandas is an open-source Python library used for knowledge manipulation and wrangling. It’s quick and really environment friendly and has instruments to load various kinds of knowledge into reminiscence. It may be used to reshape, label, index, and even group totally different types of knowledge.
Information buildings in pandas
There are 3 knowledge buildings in Pandas, particularly;
- Collection
- DataFrame
- Panel
One of the best ways to inform the three aside is to see that one comprises a number of stacks of the opposite. So a DataFrame is a stack of collection and a panel is a stack of DataFrames.
An array is a one-dimensional array
A stack of a number of strings types a 2-dimensional DataFrame
A stack of a number of knowledge frames types a three-dimensional panel
The info construction we’d work with essentially the most is the two-dimensional DataFrame, which can be the default illustration for some datasets we could encounter.
Information Evaluation in Pandas
No set up is required for this merchandise. We’d use a device referred to as Cooperative made by Google. It’s an internet python surroundings for knowledge analytics, machine studying and AI. It is only a cloud-based Jupyter pocket book that comes pre-installed with virtually each python bundle you’d want as an information scientist.
Now go to https://colab.analysis.google.com/notebooks/intro.ipynb. You need to see the beneath.

Within the high left navigation, click on on the file choice and click on on the “new pocket book” choice. You need to see a brand new Jupyter pocket book web page load in your browser. The very first thing we have to do is import pandas into our working surroundings. We will try this by operating the next code;
import pandas as pdFor this text, we’d use a home value dataset for our knowledge evaluation. The dataset we’d use may be discovered right here. The very first thing we wish to do is load this dataset into our surroundings.
We will try this with the next code in a brand new cell;
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')The .read_csv is used after we need to learn a CSV file and we handed a sep property to point that the CSV file is comma separated.
We also needs to take into account that our loaded CSV file is saved in a variable df .
We do not have to make use of the print() perform in Jupyter Pocket book. We will simply sort a variable title into our cell and Jupyter Pocket book will print it for us.
We will attempt that out by typing df in a brand new cell and operating it, it can print all the info in our dataset as a DataFrame to us.
However we do not at all times need to see all the info, generally we simply need to see the primary few knowledge and their column names. We will do the df.head() perform to print the primary 5 columns and df.tail() to print the final 5. The output from one of many two would appear to be this;
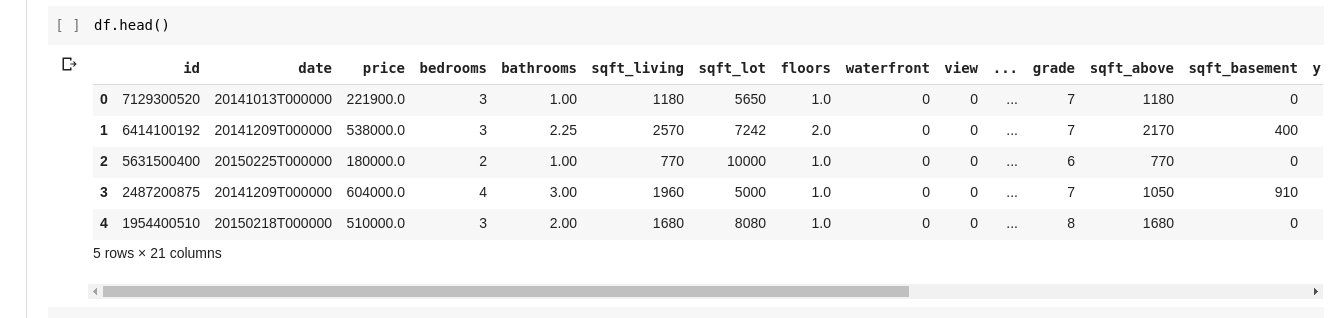
We wish to examine for relationships between these totally different rows and columns of knowledge. The .describe() perform does precisely this for us.
Operating df.describe() provides the next output;
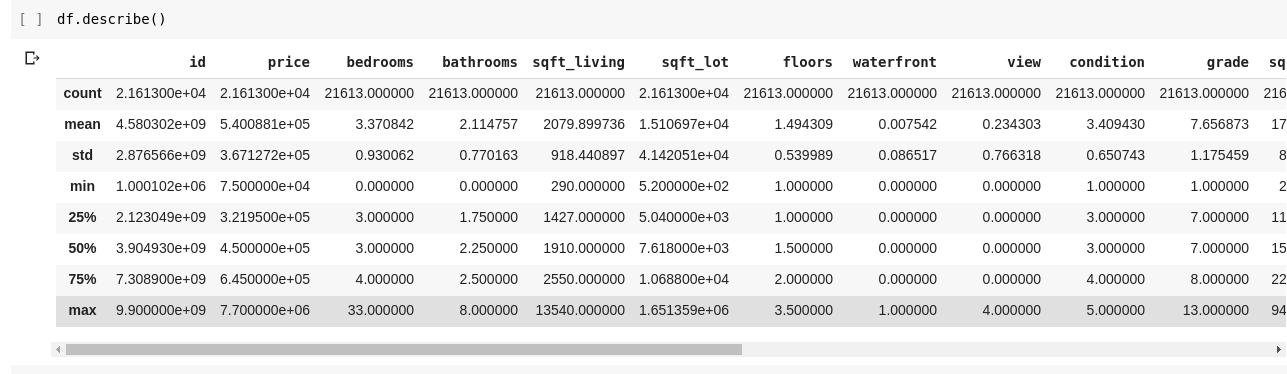
We instantly see that the .describe() returns the imply, normal deviation, minimal and most values, and percentiles of every column within the DataFrame. That is particularly very helpful.
We will additionally examine the form of our 2D DataFrame to learn the way many rows and columns it has. We will try this utilizing df.form which returns a tuple within the format (rows, columns).
We will additionally examine the names of all columns in our DataFrame utilizing df.columns.
What if we simply need to choose one column and return all knowledge in it? That is finished in a way much like shopping a dictionary. Kind the next code in a brand new cell and run it
df['price ']The code above returns the value column, we are able to take it additional by storing it as such in a brand new variable
value = df['price']Now we are able to carry out another motion that may be carried out on a DataFrame on our value variable, because it’s only a subset of an actual DataFrame. We will do issues like df.head(), df.form and many others..
We will additionally choose a number of columns by passing a listing of column names as such in df
knowledge = df[['price ', 'bedrooms']]The above selects columns named ‘value’ and ‘bedrooms’, as we sort knowledge.head() in a brand new cell, we’d have the next
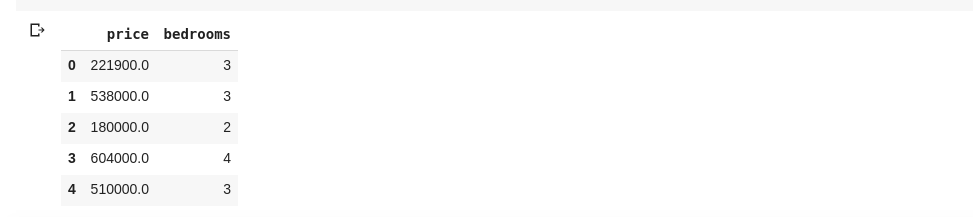
The above method of splitting columns returns all row parts in that column. What if we need to return a subset of rows and a subset of columns from our dataset? This may be finished utilizing .iloc and is listed in a way much like python lists. So we are able to do one thing like that
df.iloc[50: , 3]That returns the third column from the fiftieth row to the top. It is fairly neat and similar to slicing lists in python.
Now let’s do some actually fascinating issues, our home value knowledge set has a column that tells us the value of a home and one other column tells us the variety of bedrooms a given home has. The home value is a steady worth, so we could not have two homes which have the identical value. However the variety of bedrooms is considerably discreet, so we are able to have a number of homes with two, three, 4 bedrooms, and many others.
What if we need to get all homes with the identical variety of bedrooms and discover the common value of every particular person bed room? With pandas it’s comparatively simple to do this, it can be finished as such;
df.groupby('bedrooms ')['price '].imply()The above first teams the DataFrame through the use of the datasets with an identical bed room quantity df.groupby() perform, then we inform it to offer us simply the bed room column and the .imply() perform to search out the common of every home within the knowledge set.
What if we need to visualize the above? We wish to have the ability to examine how the common value of every particular person bed room quantity varies? We simply must hyperlink the earlier code to a .plot() perform as such;
df.groupby('bedrooms ')['price '].imply().plot()We’ve got an output that appears like this;
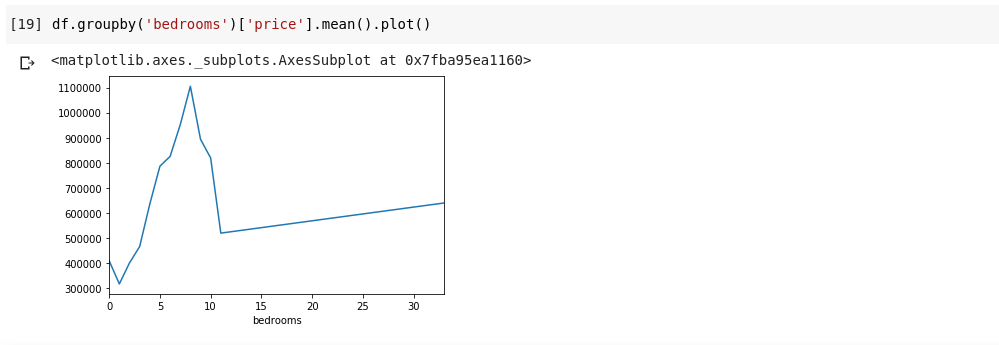
The above reveals us some tendencies within the knowledge. On the horizontal axis we now have a transparent variety of bedrooms (Word, a couple of home can have X variety of bedrooms), On the vertical axis we now have the common of the costs with respect to the corresponding variety of bedrooms on the horizontal axis. We instantly discover that homes with 5 to 10 bedrooms are much more costly than homes with 3 bedrooms. It can additionally grow to be clear that homes with 7 or 8 bedrooms price rather more than homes with 15, 20 and even 30 rooms.
Data just like the above is why knowledge evaluation is essential, we’re capable of extract helpful insights from the info that aren’t instantly or virtually unattainable to note with out evaluation.
Lacking knowledge
Let’s assume I am taking a survey that consists of a collection of questions. I am sharing a hyperlink to the survey with 1000’s of individuals to allow them to present their suggestions. My final aim is to carry out knowledge evaluation on this knowledge in order that I can extract some necessary insights from the info.
Now rather a lot can go unsuitable, some surveyors could really feel uncomfortable answering a few of my questions and depart it clean. Many individuals might do the identical for various elements of my survey questions. This might not be thought of an issue, however think about if I had been amassing numerical knowledge in my survey and a part of the evaluation required me to get the sum, common, or another arithmetic operation. A number of lacking values would result in plenty of inaccuracies in my evaluation, I must discover a strategy to discover these lacking values and exchange them with some values that may be a very good alternative for them.
Pandas present us with a perform to search out lacking values in a DataFrame referred to as isnull().
The isnull() perform can be utilized as such;
df.isnull()This returns a DataFrame of booleans that tells us whether or not the info initially current there was actually lacking or was lacking in error. The output would appear to be this;
We want a method to have the ability to exchange all these lacking values, normally the selection of lacking values may be taken as zero. Typically it may be taken as the common of all different knowledge or maybe the common of the info round it, relying on the info scientist and the use case of the info being analyzed.
To fill all lacking values in a DataFrame, we use the .fillna() perform used as such;
df.fillna(0)Within the above, we fill all empty knowledge with the worth zero. It’d as effectively be another quantity we specify.
The significance of knowledge can’t be overemphasized, it helps us get solutions straight from our knowledge itself!. In accordance with them, knowledge analytics is the brand new oil for digital economies.
All examples on this article may be discovered right here.
Take a look at the Information Evaluation with Python and Pandas on-line course for extra data.