
Assist Vector Machine is een van de meest populaire Machine Studying-algoritmen. Het is efficiënt en kan trainen in beperkte datasets. Maar wat is het?
Wat is een ondersteuningsvectormachine (SVM)?
Assist vector machine is een machine learning-algoritme dat gebruik maakt van begeleid leren om een mannequin voor binaire classificatie te creëren. Dat is een mondvol. In dit artikel wordt SVM uitgelegd en hoe dit zich verhoudt tot natuurlijke taalverwerking. Maar laten we eerst analyseren hoe een ondersteuningsvectormachine werkt.
Hoe werkt SVM?
Beschouw een eenvoudig classificatieprobleem waarbij we gegevens hebben met twee kenmerken, x en y, en één uitvoer: een classificatie die rood of blauw is. We kunnen een denkbeeldige dataset plotten die er als volgt uitziet:
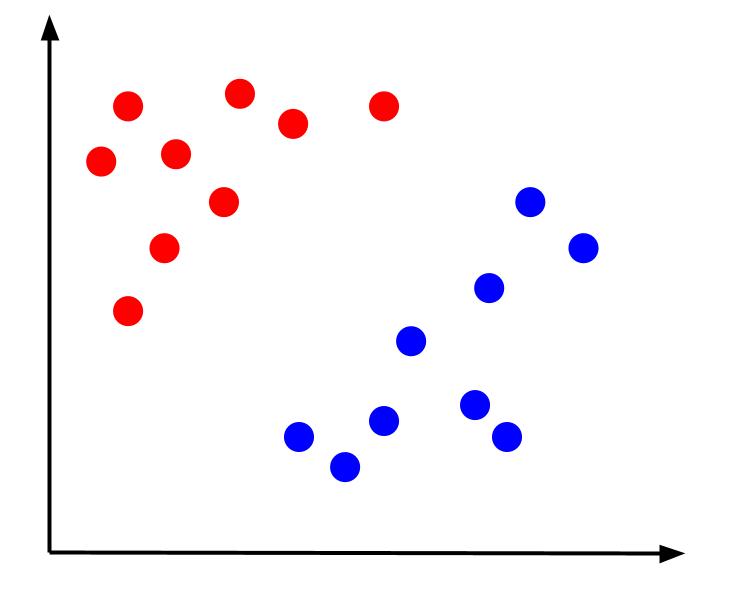
Gegeven dit soort gegevens zou het de taak zijn om een beslissingsgrens te creëren. Een beslissingsgrens is een lijn die de twee klassen van onze gegevenspunten scheidt. Dit is dezelfde dataset, maar met een beslissingsgrens:
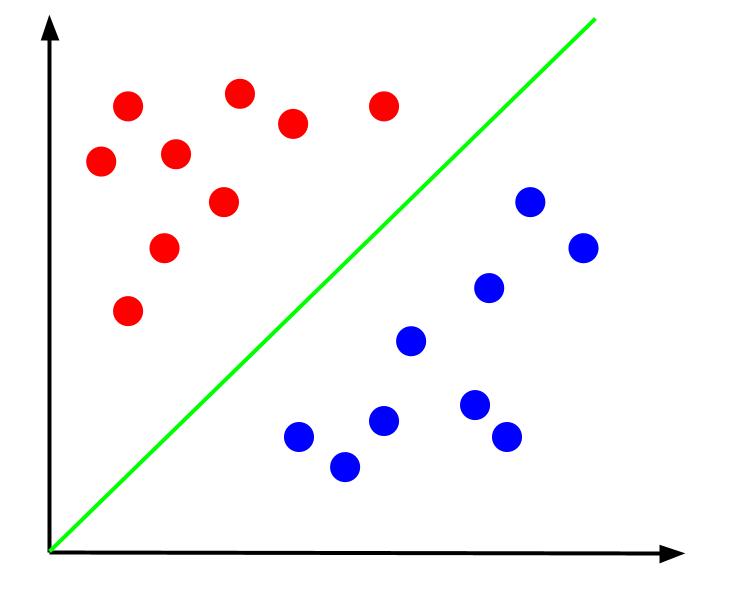
Met deze beslissingsgrens kunnen we vervolgens voorspellingen doen voor welke klasse een datapunt behoort, gegeven waar het ligt ten opzichte van de beslissingsgrens. Het Assist Vector Machine-algoritme creëert de beste beslissingsgrens die zal worden gebruikt om punten te classificeren.
Maar wat bedoelen we met de beste beslissingsgrens?
Er kan worden beargumenteerd dat de beste beslissingsgrens degene is die de afstand tot een van de steunvectoren maximaliseert. Ondersteuningsvectoren zijn gegevenspunten van een van de klassen die het dichtst bij de tegenovergestelde klasse liggen. Deze datapunten vormen het grootste risico op verkeerde classificatie vanwege hun nabijheid tot de andere klasse.
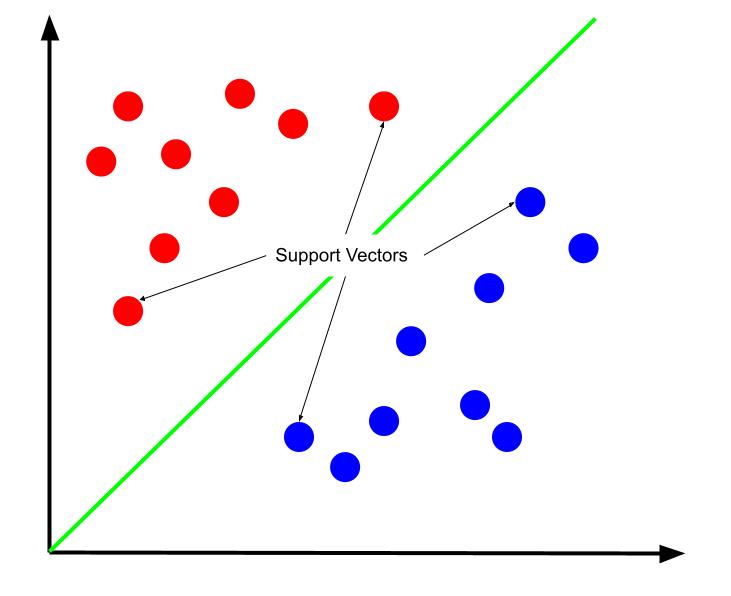
Het trainen van een ondersteuningsvectormachine houdt daarom in dat je probeert een lijn te vinden die de marge tussen ondersteuningsvectoren maximaliseert.
Het is ook belangrijk op te merken dat, omdat de beslissingsgrens is gepositioneerd ten opzichte van de steunvectoren, deze de enige determinanten zijn van de positie van de beslissingsgrens. De overige datapunten zijn daarom redundant. En dus vereist coaching alleen de ondersteunende vectoren.
In dit voorbeeld is de gevormde beslissingsgrens een rechte lijn. Dit komt alleen omdat de dataset slechts twee kenmerken heeft. Wanneer de dataset drie kenmerken heeft, is de gevormde beslissingsgrens een vlak in plaats van een lijn. En als het vier of meer kenmerken heeft, staat de beslissingsgrens bekend als een hypervlak.
Niet-lineair scheidbare gegevens
In het bovenstaande voorbeeld zijn zeer eenvoudige gegevens beschouwd die, wanneer ze worden geplot, kunnen worden gescheiden door een lineaire beslissingsgrens. Beschouw een ander geval waarin gegevens als volgt worden uitgezet:

In dit geval is het onmogelijk om de gegevens te scheiden door middel van een lijn. Maar we kunnen nog een ander kenmerk creëren, z. En dit kenmerk kan worden gedefinieerd door de vergelijking: z = x^2 + y^2. We kunnen z als derde as aan het vlak toevoegen om het driedimensionaal te maken.
Als we vanuit een zodanige hoek naar de 3D-plot kijken dat de x-as horizontaal is terwijl de z-as verticaal is, is dit het beeld dat we krijgen dat er ongeveer zo uitziet:
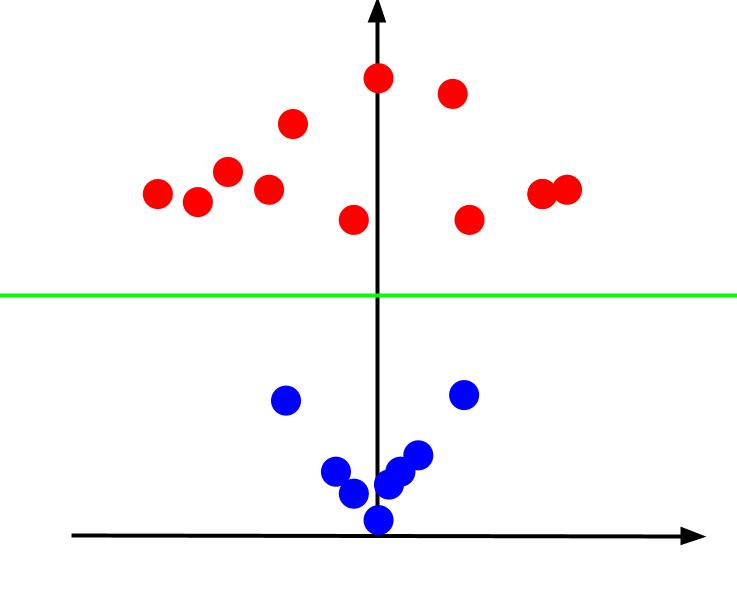
De z-waarde geeft aan hoe ver een punt verwijderd is van de oorsprong ten opzichte van de andere punten in het oude XY-vlak. Als gevolg hiervan hebben de blauwe punten dichter bij de oorsprong lage z-waarden.
Hoewel de rode punten verder van de oorsprong hogere z-waarden hadden, geeft het uitzetten ervan tegen hun z-waarden ons een duidelijke classificatie die kan worden afgebakend door een lineaire beslissingsgrens, zoals geïllustreerd.
Dit is een krachtig idee dat wordt gebruikt in Assist Vector Machines. Meer in het algemeen is het het idee om de dimensies in een groter aantal dimensies in kaart te brengen, zodat gegevenspunten kunnen worden gescheiden door een lineaire grens. Functies die hiervoor verantwoordelijk zijn zijn kernelfuncties. Er zijn veel kernelfuncties, zoals sigmoïde, lineair, niet-lineair en RBF.
Om het in kaart brengen van deze functies efficiënter te maken, gebruikt SVM een kerneltruc.
SVM in machinaal leren
Assist Vector Machine is een van de vele algoritmen die worden gebruikt bij machine studying, naast populaire algoritmen zoals Resolution Timber en Neural Networks. Het heeft de voorkeur omdat het goed werkt met minder gegevens dan andere algoritmen. Het wordt vaak gebruikt om het volgende te doen:
- Tekstclassificatie: tekstgegevens zoals opmerkingen en recensies indelen in een of meer categorieën
- Gezichtsherkenning: afbeeldingen analyseren om gezichten te detecteren en dingen te doen zoals het toevoegen van filters voor augmented actuality
- Beeldclassificatie: Ondersteuningsvectormachines kunnen afbeeldingen efficiënt classificeren in vergelijking met andere benaderingen.
Het tekstclassificatieprobleem
Het web staat vol met heel veel tekstuele gegevens. Veel van deze gegevens zijn echter ongestructureerd en ongelabeld. Om deze tekstgegevens beter te kunnen gebruiken en beter te begrijpen, is er behoefte aan classificatie. Voorbeelden van momenten waarop tekst wordt geclassificeerd zijn:
- Wanneer tweets worden onderverdeeld in onderwerpen, zodat mensen de onderwerpen kunnen volgen die ze willen
- Wanneer een e-mail is gecategoriseerd als Sociaal, Promoties of Spam
- Wanneer reacties op openbare boards als haatdragend of obsceen worden geclassificeerd
Hoe SVM werkt met natuurlijke taalclassificatie
Assist Vector Machine wordt gebruikt om tekst te classificeren in tekst die bij een bepaald onderwerp hoort en tekst die niet bij het onderwerp hoort. Dit wordt bereikt door de tekstgegevens eerst te converteren en weer te geven in een dataset met verschillende functies.
Eén manier om dit te doen is door options te creëren voor elk woord in de dataset. Vervolgens registreert u voor elk tekstgegevenspunt het aantal keren dat elk woord voorkomt. Stel dus dat er unieke woorden voorkomen in de dataset; u zult functies in de dataset hebben.
Daarnaast geef je classificaties voor deze datapunten. Hoewel deze classificaties per tekst zijn gelabeld, verwachten de meeste SVM-implementaties numerieke labels.
Daarom zul je deze labels vóór de coaching naar cijfers moeten converteren. Zodra de dataset is voorbereid en deze kenmerken als coördinaten zijn gebruikt, kunt u een SVM-model gebruiken om de tekst te classificeren.
Een SVM maken in Python
Om een help vector machine (SVM) in Python te maken, kunt u de SVC klasse uit de sklearn.svm bibliotheek. Hier is een voorbeeld van hoe u de SVC klasse om een SVM-model in Python te bouwen:
from sklearn.svm import SVC
# Load the dataset
X = ... y = ...
# Break up the information into coaching and check units
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Create an SVM mannequin
mannequin = SVC(kernel='linear')
# Prepare the mannequin on the coaching information
mannequin.match(X_train, y_train)
# Consider the mannequin on the check information
accuracy = mannequin.rating(X_test, y_test)
print("Accuracy: ", accuracy) In dit voorbeeld importeren we eerst de SVC klasse uit de sklearn.svm bibliotheek. Vervolgens laden we de dataset en splitsen deze op in trainings- en testsets.
Vervolgens creëren we een SVM-model door een SVC object en specificeer de kernel parameter als ‘lineair’. Vervolgens trainen we het mannequin op de trainingsgegevens met behulp van de match methode en evalueer het mannequin op foundation van de testgegevens met behulp van de rating methode. De rating methode retourneert de nauwkeurigheid van het mannequin, die we naar de console afdrukken.
U kunt ook andere parameters opgeven voor de SVC voorwerp, zoals de C parameter die de sterkte van de regularisatie regelt, en de gamma parameter, die de kernelcoëfficiënt voor bepaalde kernels regelt.
Voordelen van SVM
Hier is een lijst met enkele voordelen van het gebruik van Assist Vector Machines (SVM’s):
- Efficiënt: SVM’s zijn over het algemeen efficiënt om te trainen, vooral als het aantal monsters groot is.
- Robuust tegen ruis: SVM’s zijn relatief robuust tegen ruis in de trainingsgegevens, omdat ze proberen de maximale marge-classificator te vinden, die minder gevoelig is voor ruis dan andere classificatoren.
- Geheugen efficiënt: SVM’s vereisen slechts een subset van de trainingsgegevens die zich op een bepaald second in het geheugen bevinden, waardoor ze geheugenefficiënter zijn dan andere algoritmen.
- Effectief in hoogdimensionale ruimtes: SVM’s kunnen nog steeds goed presteren, zelfs als het aantal functies het aantal samples overschrijdt.
- Veelzijdigheid: SVM’s kunnen worden gebruikt voor classificatie- en regressietaken en kunnen verschillende soorten gegevens verwerken, inclusief lineaire en niet-lineaire gegevens.
Laten we nu enkele van de beste bronnen verkennen om Assist Vector Machine (SVM) te leren kennen.
Leermiddelen
Een inleiding tot de ondersteuning van vectormachines
Dit boek over Inleiding tot het ondersteunen van vectormachines laat u uitgebreid en geleidelijk kennismaken met kernelgebaseerde leermethoden.
| Voorbeeld | Product | Beoordeling | Prijs | |
|---|---|---|---|---|
|
|
Een inleiding tot de ondersteuning van vectormachines en andere kernelgebaseerde leermethoden |
$ 69,00 |
Koop op Amazon |

Het geeft je een stevige foundation in de Assist Vector Machines-theorie.
Ondersteuning van vectormachinetoepassingen
Terwijl het eerste boek zich concentreerde op de theorie van Assist Vector Machines, richt dit boek over Assist Vector Machines-toepassingen zich op hun praktische toepassingen.
| Voorbeeld | Product | Beoordeling | Prijs | |
|---|---|---|---|---|
|
|
Ondersteuning van vectormachinetoepassingen |
$ 87,46 |
Koop op Amazon |

Er wordt gekeken naar hoe SVM’s worden gebruikt bij beeldverwerking, patroondetectie en computervisie.
Ondersteuning van vectormachines (informatiewetenschap en statistiek)
Het doel van dit boek over Assist Vector Machines (Informatiewetenschap en Statistiek) is om een overzicht te geven van de principes achter de effectiviteit van Assist Vector Machines (SVM’s) in verschillende toepassingen.
| Voorbeeld | Product | Beoordeling | Prijs | |
|---|---|---|---|---|
|
|
Ondersteuning van vectormachines (informatiewetenschap en statistiek) |
$ 152,47 |
Koop op Amazon |

De auteurs benadrukken verschillende factoren die bijdragen aan het succes van SVM’s, waaronder hun vermogen om goed te presteren met een beperkt aantal instelbare parameters, hun weerstand tegen verschillende soorten fouten en afwijkingen, en hun efficiënte rekenprestaties in vergelijking met andere methoden.
Leren met kernels
“Studying with Kernels” is een boek dat lezers kennis laat maken met de ondersteuning van vectormachines (SVM’s) en gerelateerde kerneltechnieken.
| Voorbeeld | Product | Beoordeling | Prijs | |
|---|---|---|---|---|
|
|
Leren met kernels: ondersteuning van vectormachines, regularisatie, optimalisatie en meer (adaptief… |
$ 80,00 |
Koop op Amazon |

Het is ontworpen om lezers een basiskennis van wiskunde te geven en de kennis die ze nodig hebben om kernelalgoritmen te gaan gebruiken in machinaal leren. Het boek heeft tot doel een grondige maar toegankelijke introductie te bieden tot SVM’s en kernelmethoden.
Ondersteun vectormachines met Sci-kit Be taught
Deze on-line Assist Vector Machines met Sci-kit Be taught-cursus van het Coursera-projectnetwerk leert hoe u een SVM-model kunt implementeren met behulp van de populaire machine learning-bibliotheek, Sci-Equipment Be taught.

Daarnaast leer je de theorie achter SVM’s en bepaal je hun sterke en zwakke punten. De cursus is op beginnersniveau en duurt ongeveer 2,5 uur.
Ondersteuning van vectormachines in Python: concepten en code
Deze betaalde on-line cursus over Assist Vector Machines in Python van Udemy biedt maximaal 6 uur video-gebaseerde instructie en wordt geleverd met een certificering.

Het behandelt SVM’s en hoe deze solide in Python kunnen worden geïmplementeerd. Verder omvat het zakelijke toepassingen van Assist Vector Machines.
Machine Studying en AI: ondersteuning van vectormachines in Python
In deze cursus Machine Studying en AI leert u hoe u Assist Vector Machines (SVM’s) kunt gebruiken voor verschillende praktische toepassingen, waaronder beeldherkenning, spamdetectie, medische diagnose en regressieanalyse.

Je gebruikt de programmeertaal Python om ML-modellen voor deze applicaties te implementeren.
Laatste woorden
In dit artikel leerden we kort over de theorie achter Assist Vector Machines. We leerden over de toepassing ervan in machine studying en natuurlijke taalverwerking.
We hebben ook gezien wat de implementatie ervan gebruikt scikit-learn lijkt op. Verder spraken we over de praktische toepassingen en voordelen van Assist Vector Machines.
Hoewel dit artikel slechts een introductie was, raadden de aanvullende bronnen aan om dieper in te gaan en meer uit te leggen over Assist Vector Machines. Gezien hoe veelzijdig en efficiënt ze zijn, zijn SVM’s de moeite waard om te begrijpen om te groeien als datawetenschapper en ML-ingenieur.
Vervolgens kunt u de beste machine learning-modellen bekijken.