

Amazon Glue is gaining reputation as a result of many firms have began to make use of managed knowledge integration companies.
ETL is a course of that transfers knowledge from a supply database to a knowledge warehouse. ETL is complicated and tough to implement for all enterprise knowledge resulting from its complexity. Amazon launched AWS Glue to deal with this drawback.
ETL builders and knowledge engineers use Glue to construct, monitor, and run ETL workflows.
What’s AWS Glue?
AWS Glue, a serverless data-integration service, makes it straightforward to seek out, put together, transfer and combine knowledge from a number of sources. That is helpful for machine studying (ML) and analytics.
It dramatically reduces the time required to arrange the info for evaluation. It routinely finds and lists the info, generates Scala or Python code to transmit the info from the supply, and hundreds and transforms the job in line with the timed occasions.
This permits for versatile scheduling and creates an Apache Spark atmosphere that may be scaled for focused knowledge loading. As well as, AWS Glue gives complicated knowledge stream monitoring and alteration. AWS Glue is a serverless service that simplifies utility growth’s sophisticated operations.
It permits for the short integration of a number of legitimate knowledge. It additionally breaks down and authorizes knowledge rapidly.
What’s AWS Glue used for?
It is very important know one of the best locations to make use of Amazon Glue. These are only a few examples of AWS Glue makes use of you must contemplate.
- Amazon Glue is a device that lets you run serverless queries on the Amazon S3 knowledge lakes.
- Amazon Glue is a superb device to get you began. It makes all of your knowledge accessible at one interface, permitting you to investigate it with out having to maneuver it.
- Amazon Glue can be utilized to grasp your knowledge property. Amazon Glue makes it straightforward so that you can search totally different AWS knowledge units utilizing the Knowledge Catalog. You can even save knowledge throughout a number of AWS companies utilizing the Knowledge Catalog whereas nonetheless having a constant view.
- Glue might be useful when constructing event-driven ETL workflows. You’ll be able to execute your ETL operations from Amazon S3 by calling your Glue ETL duties by way of an AWS Lambda service.
- AWS Glue will also be used to scrub, confirm, format, and arrange knowledge for storage in an information lake or warehouse.
Elements of AWS Glue
Beneath are the primary parts of AWS Glue:
- Knowledge catalog: This knowledge catalog accommodates metadata and the info construction.
- Database: That is the important thing to accessing and creating the database for sources and targets.
- Desk: Create one or a number of tables within the database which can be usable by each the goal and the supply.
- Crawler and Classifier: The crawler retrieves knowledge from the supply through the use of both built-in or {custom} classifications. It creates/makes use of pre-defined metadata tables within the knowledge catalog.
- Job: That is the job of enterprise logic to carry out an ETL activity. This enterprise logic is written internally by Apache Spark utilizing python and scala languages.
- Set off: An ETL set off is a tool that initiates the execution of an ETL job on-demand or at a specific time.
- Endpoint for growth: This creates an atmosphere through which the ETL job script is examined, developed, and debugged.
Advantages of AWS Glue
These are the advantages of utilizing it in your office or inside a corporation.
- AWS Glue scans all knowledge accessible with a crawler.
- Last processed knowledge might be saved in lots of locations (Amazon RDS and Amazon Redshift, Amazon S3, and so forth.
- It’s a cloud-based service. There is no such thing as a must spend cash on infrastructures on-premises.
- As a result of it’s a serverless ETL, it’s a cost-effective selection.
- It’s quick. It instantly provides you the Python/Scala ETL Code.
Prime Options of AWS Glue
Amazon Glue has all of the options that it is advisable to combine knowledge so you will get higher insights and use your data to make new advances in minutes as an alternative of months. Listed below are a few of the options that you must know.
- Drag and Drop Interface: A drag-and-drop job editor lets you create an ETL course of. AWS Glue will instantly construct the code wanted to extract, convert and add the info.
- Computerized Schema Discovery: To create crawlers that hook up with totally different knowledge sources, you should use the Glue service. It organizes knowledge and extracts related info. These knowledge can then be used to watch ETL processes by ETL duties.
- Job Scheduling: Glue can both be used on-demand or in line with a scheduled schedule. The scheduler can be utilized to construct complicated ETL pipelines, establishing dependencies between duties.
- Code Era: Glue Elastic Views lets you simply create materialized views that mix and replicate knowledge from totally different knowledge sources with out having to write down any proprietary code.
- Constructed-In Machine Studying: Glue comes with a built-in Machine Studying characteristic referred to as “FindMatches”. It deduplicates data that aren’t excellent copies of one another.
- Developer Endpoints: If you wish to actively develop your ETL code, Glue gives developer endpoints that help you modify, debug and check the code it creates.
- Glue DataBrew: It’s a knowledge preparation device that can be utilized by knowledge analysts and knowledge scientists to assist them clear and normalize knowledge. It makes use of Glue DataBrew’s energetic and visible interface.
How Does AWS Glue Pricing work?
AWS Glue costs an hourly price, which is billed per second for crawlers (discovering the info) and ETL jobs (processing and loading the info). A easy month-to-month price is charged for accessing and storing metadata within the AWS Glue Knowledge Catalog.
Amazon Glue begins at $0.44. You’ll be able to select from 4 plans:
- ETL duties, growth endpoints, and different ETL duties can be found at $0.44
- Crawlers Interactive Periods are Obtainable at $0.44
- DataBrew jobs begin at $0.48
- Month-to-month storage and requests to the Knowledge Catalog price $1.00
AWS doesn’t provide a free Glue plan. Every hour will price $0.44 per DPU. On common, it might price you $21 per day. Costs can differ relying on the place you reside.
Steps to Arrange AWS Glue
The Knowledge Catalog can be utilized to rapidly discover and search a number of AWS datasets with out having to maneuver the info. After the info has been cataloged, they’re instantly accessible for question and search utilizing Amazon Athena and Amazon EMR.
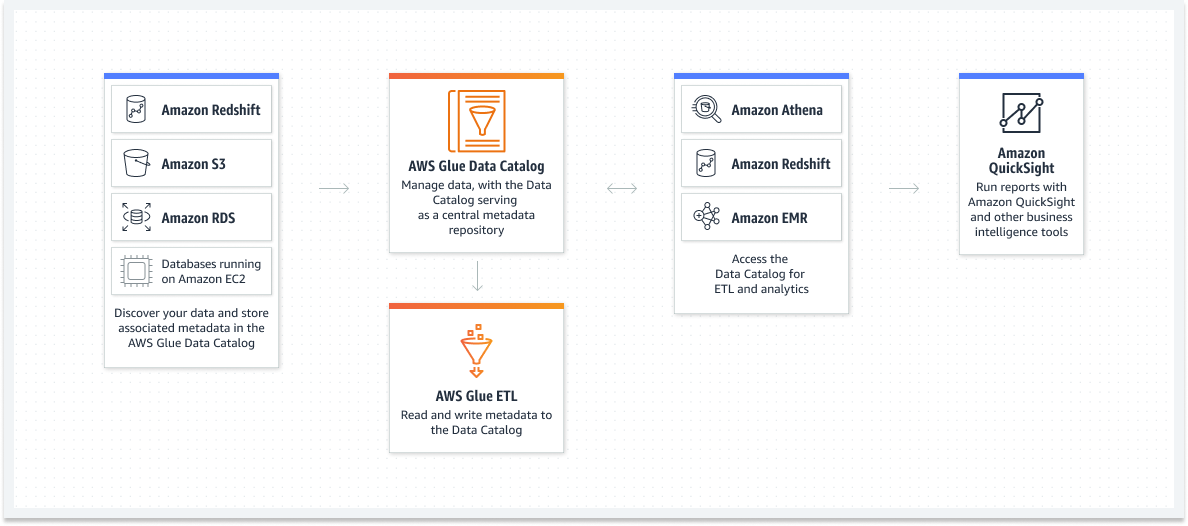
- Amazon Redshift, Amazon S3, Amazon RDS, and Databases on Amazon EC2 – Uncover your knowledge, retailer metadata, and use the AWS Glue Knowledge Catalog to find them
- AWS Glue Knowledge Catalog – Handle knowledge with the info catalog performing as a central repository for metadata
- AWS Glue ETL – Learn and write metadata to your knowledge catalog
- Amazon Athena and Amazon Redshift, Amazon EMR, Amazon ETL – Get the info catalog for ETL, analytics, and extra.
- Amazon QuickSight – Run reviews with Amazon QuickSight, and different enterprise intelligence instruments
Learn how to Setup AWS Glue?
Firstly, Signal into the AWS Administration Console and open the IAM console. Click on on Create function. Then for function sort, discover Glue, and choose Permissions.
I’m selecting AWSGlueServiceRole for common AWS Glue Studio and AWS Glue permissions and the AWS-managed coverage AmazonS3FullAccess for entry to Amazon S3 assets.
Enter a task title.
Click on on Create Position.
Create an Amazon S3 bucket.
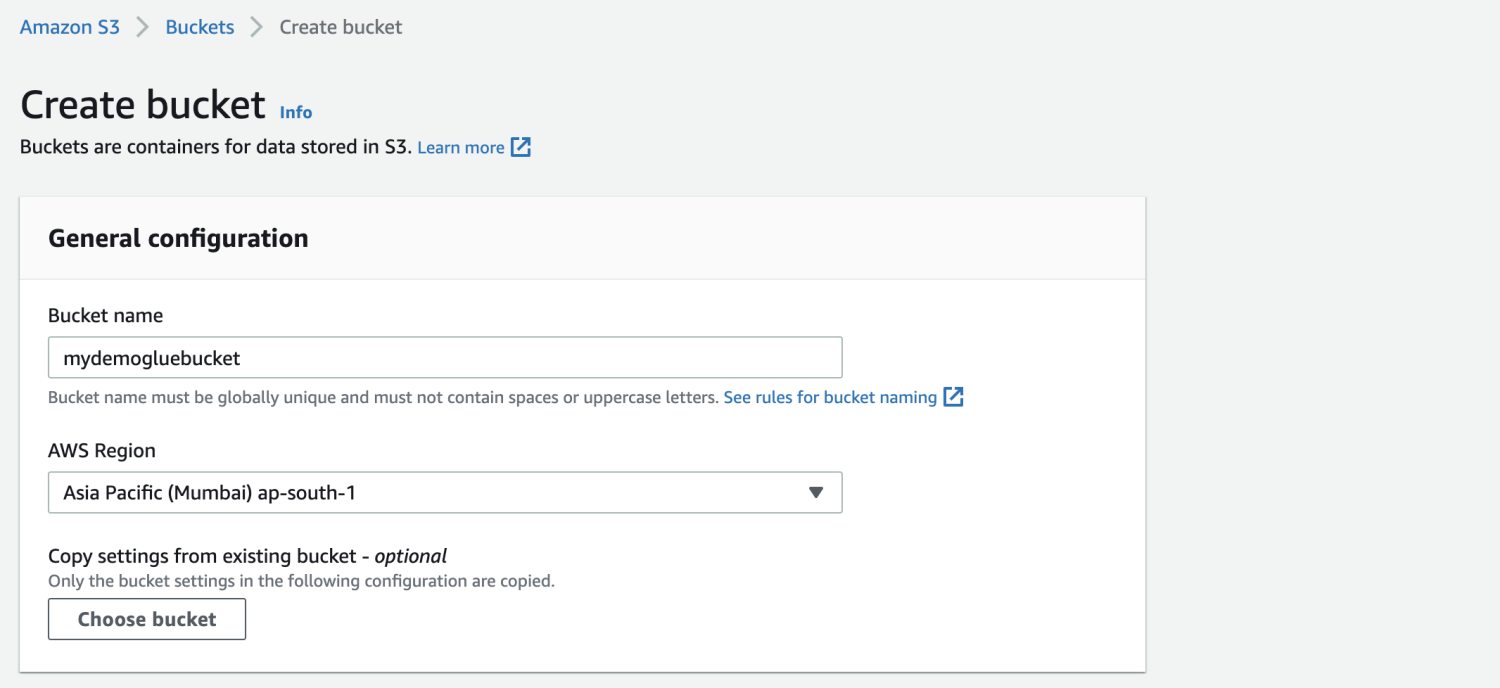
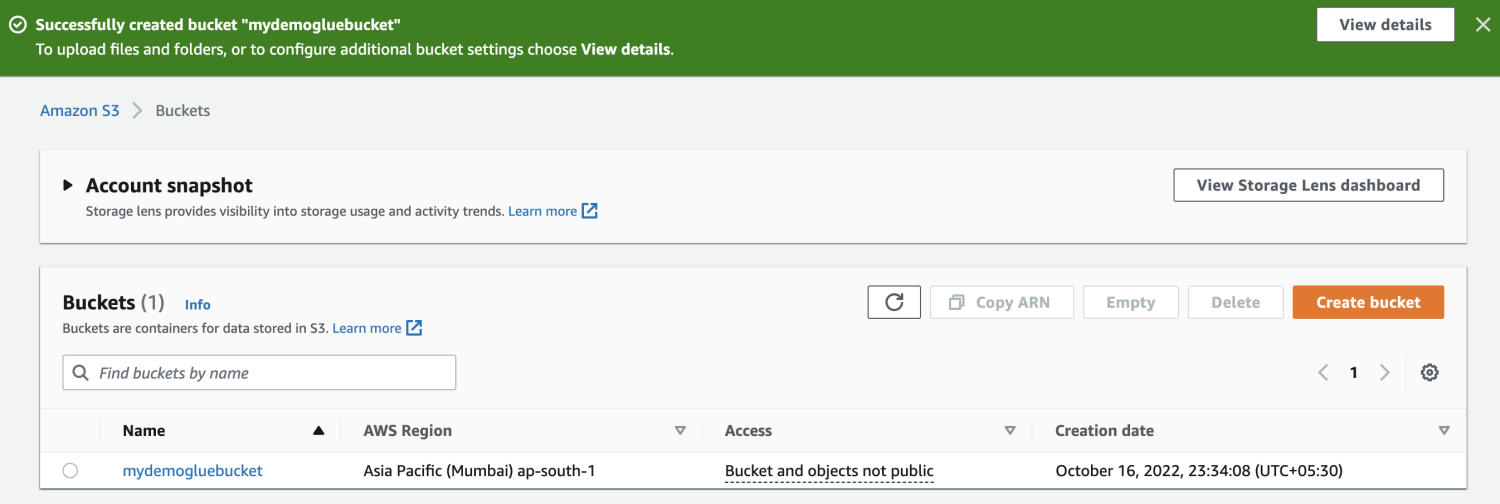
Create a folder contained in the S3 bucket.
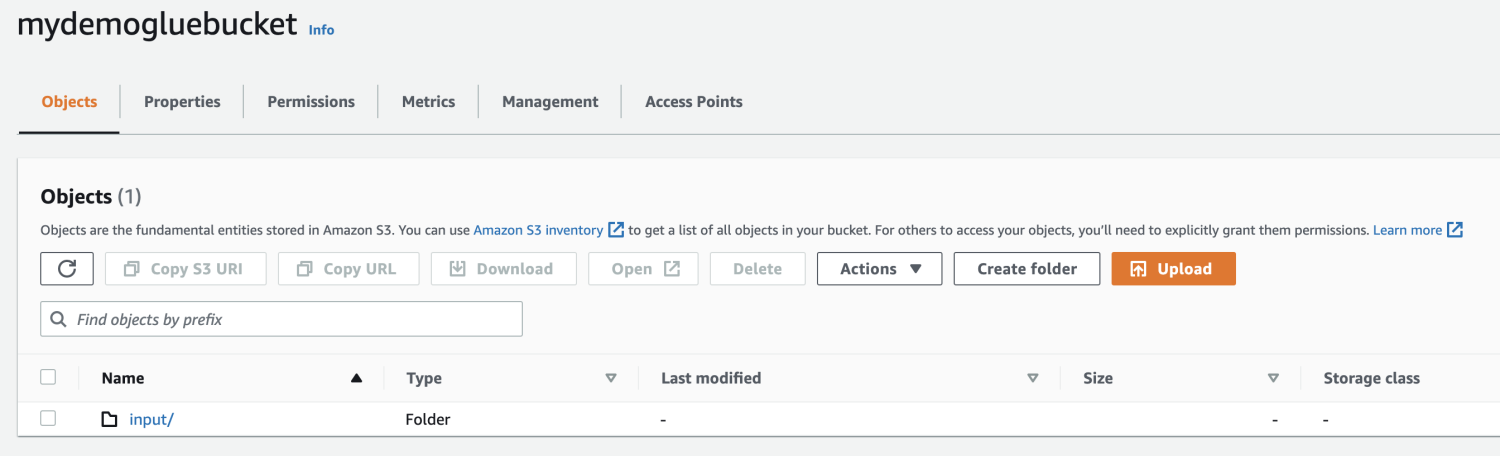
Select the file to add.
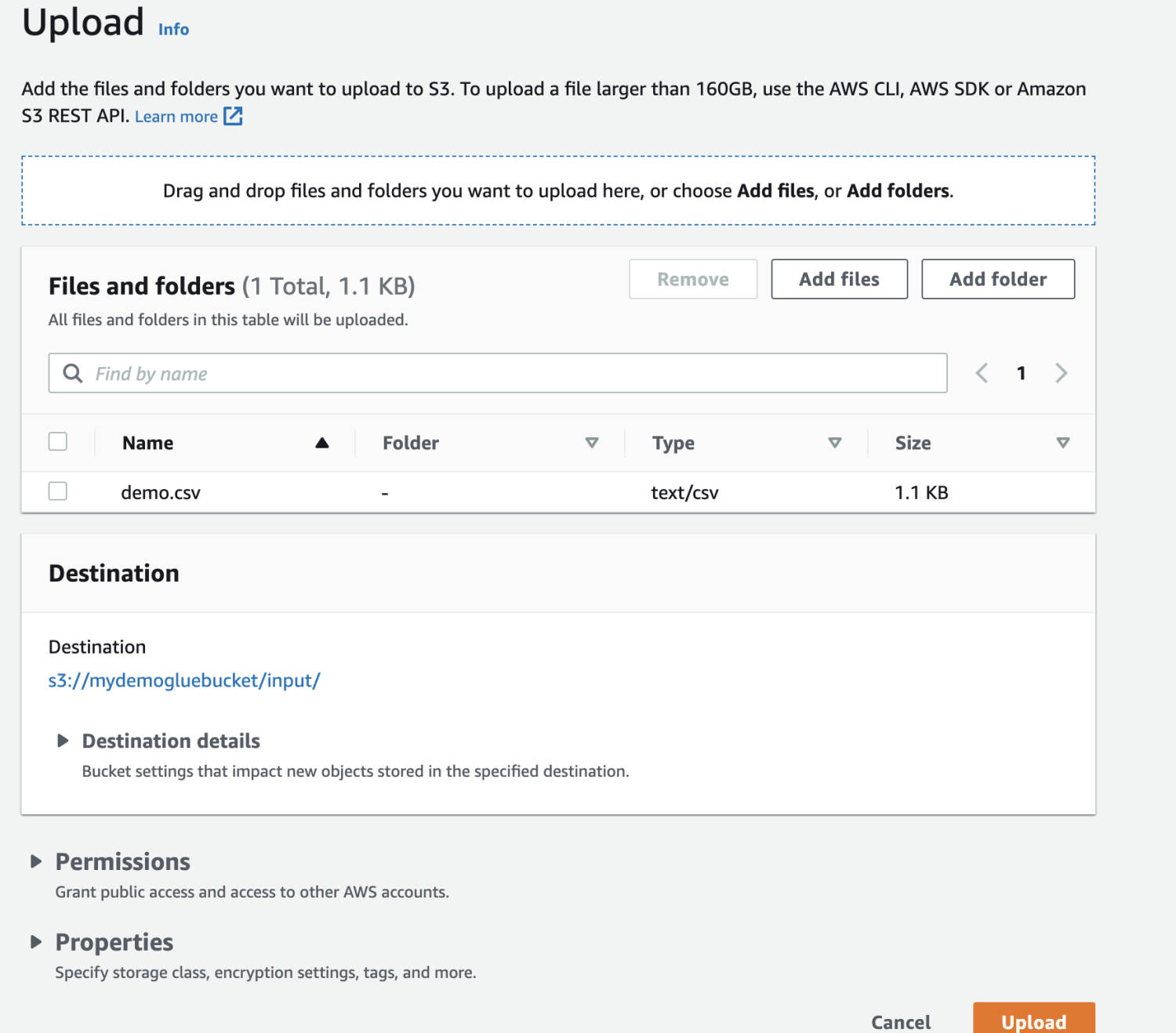
Lastly, add the file within the bucket.
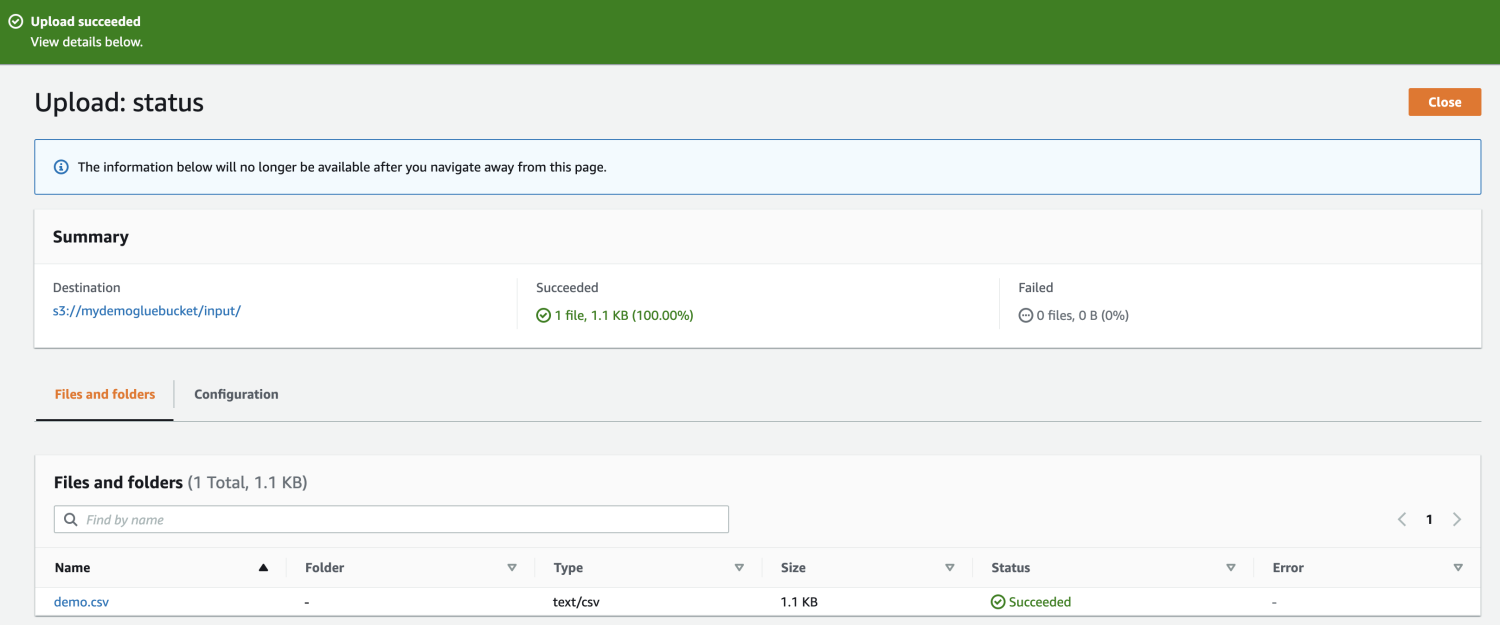
Subsequent, open AWS Glue from the AWS administration console and create a database.
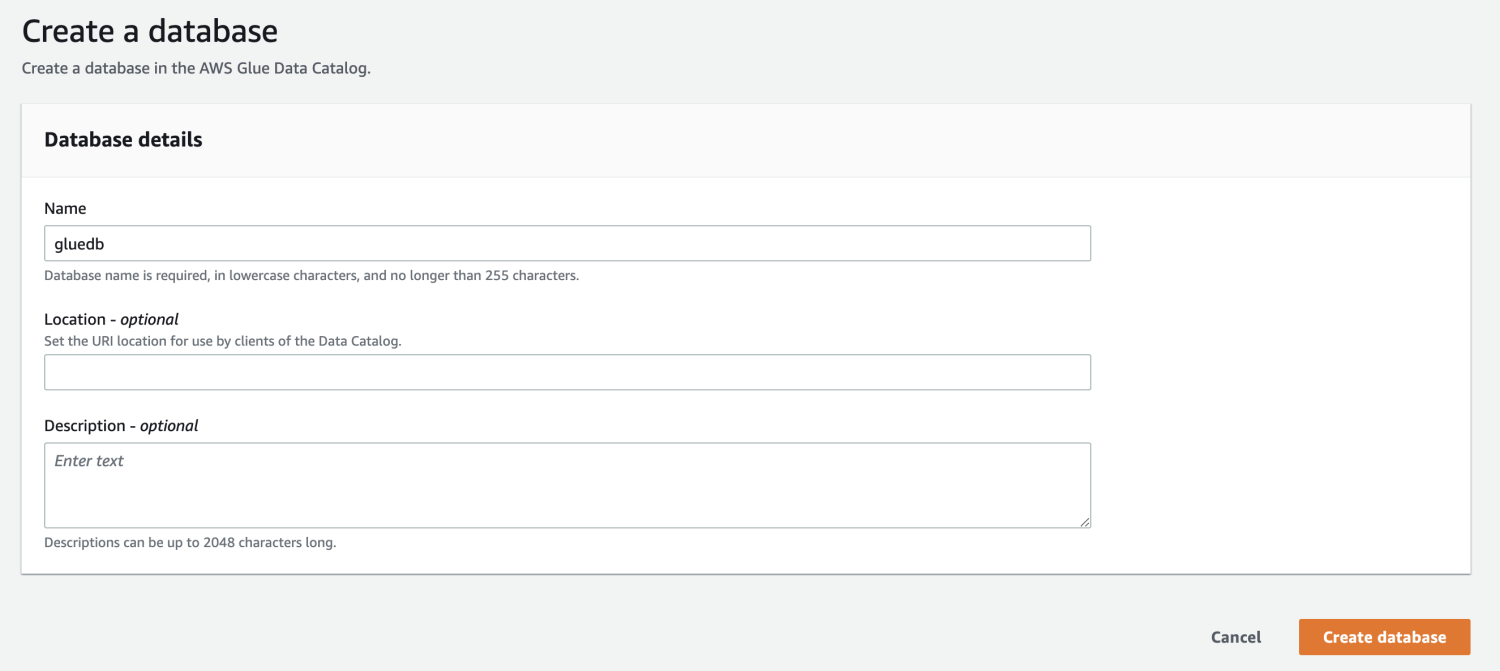
Now that you’ve got a database in AWS Glue, create a crawler.
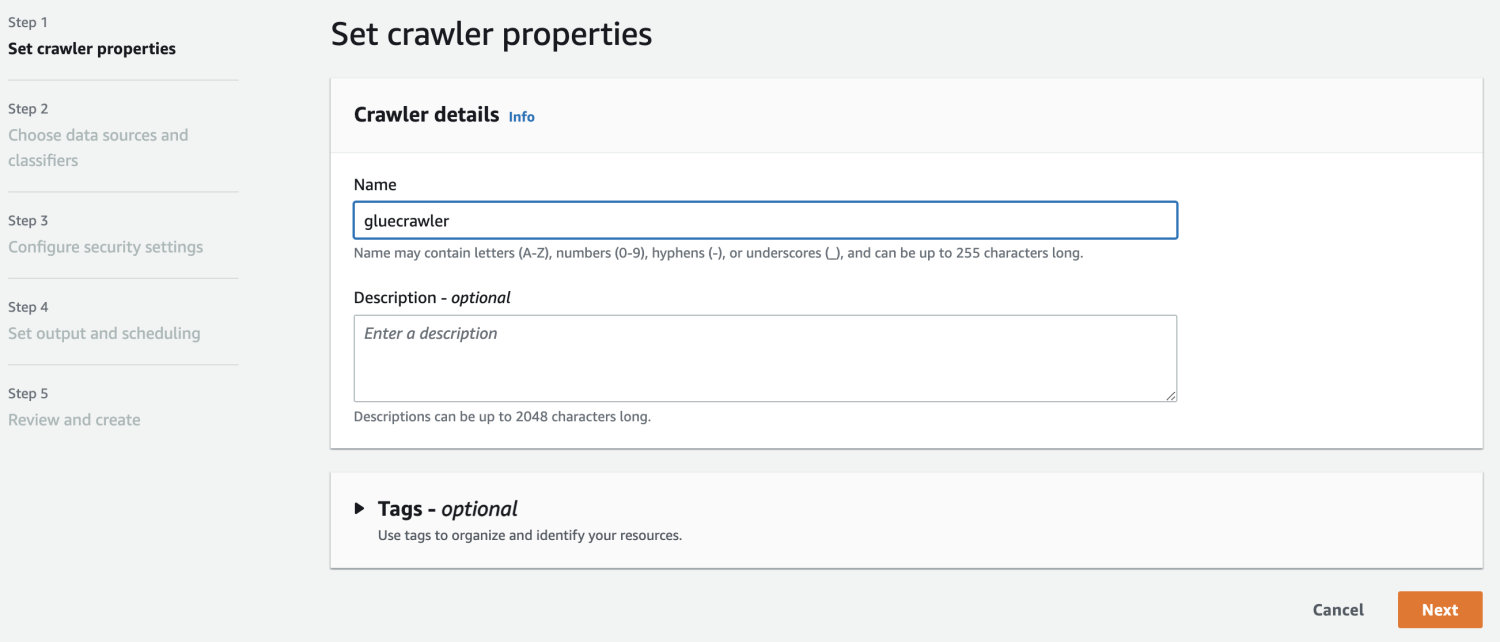
Within the knowledge supply, choose the S3 bucket which you created.
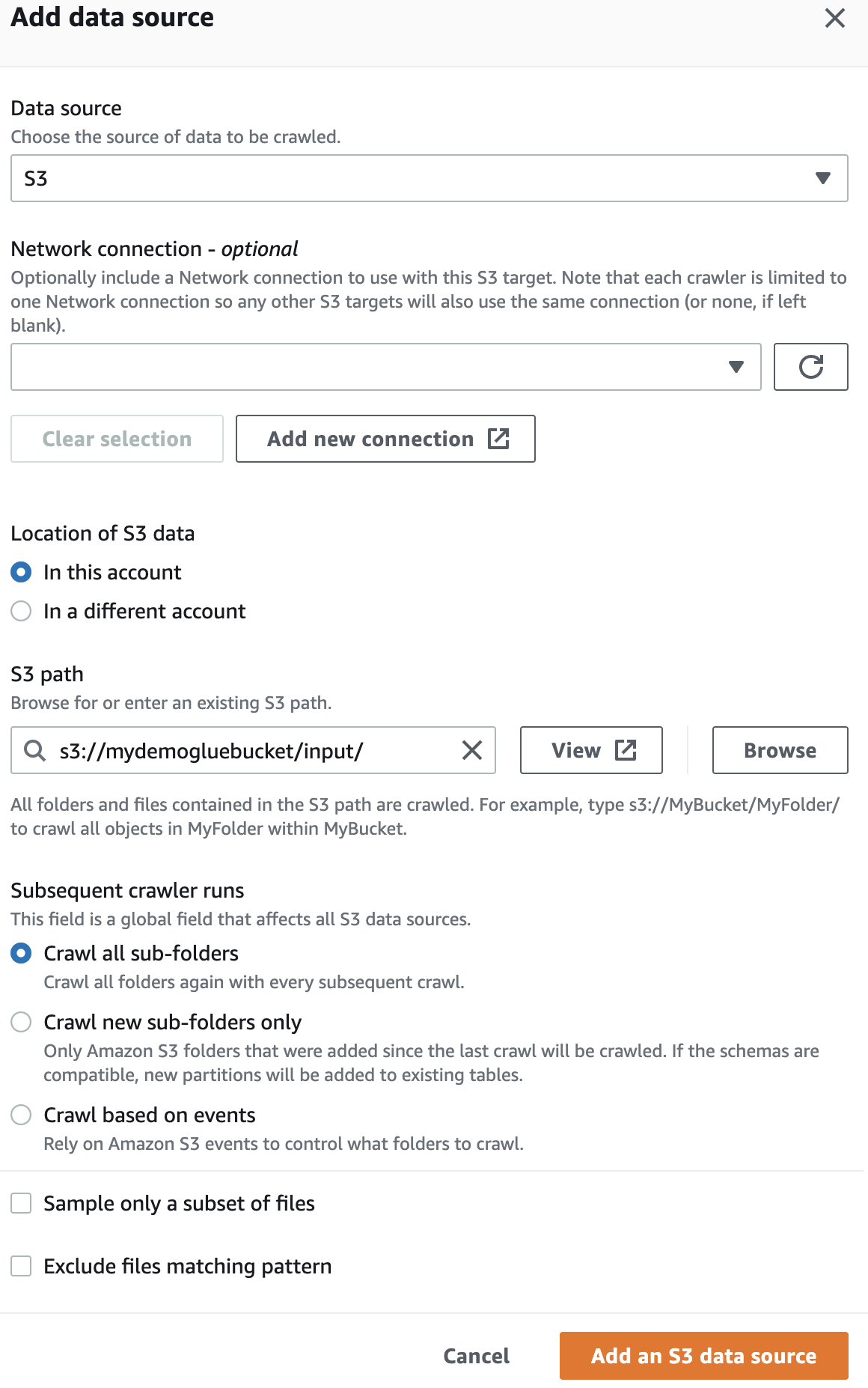
Subsequent, choose the IaM function for AWS Glue which you created at first.
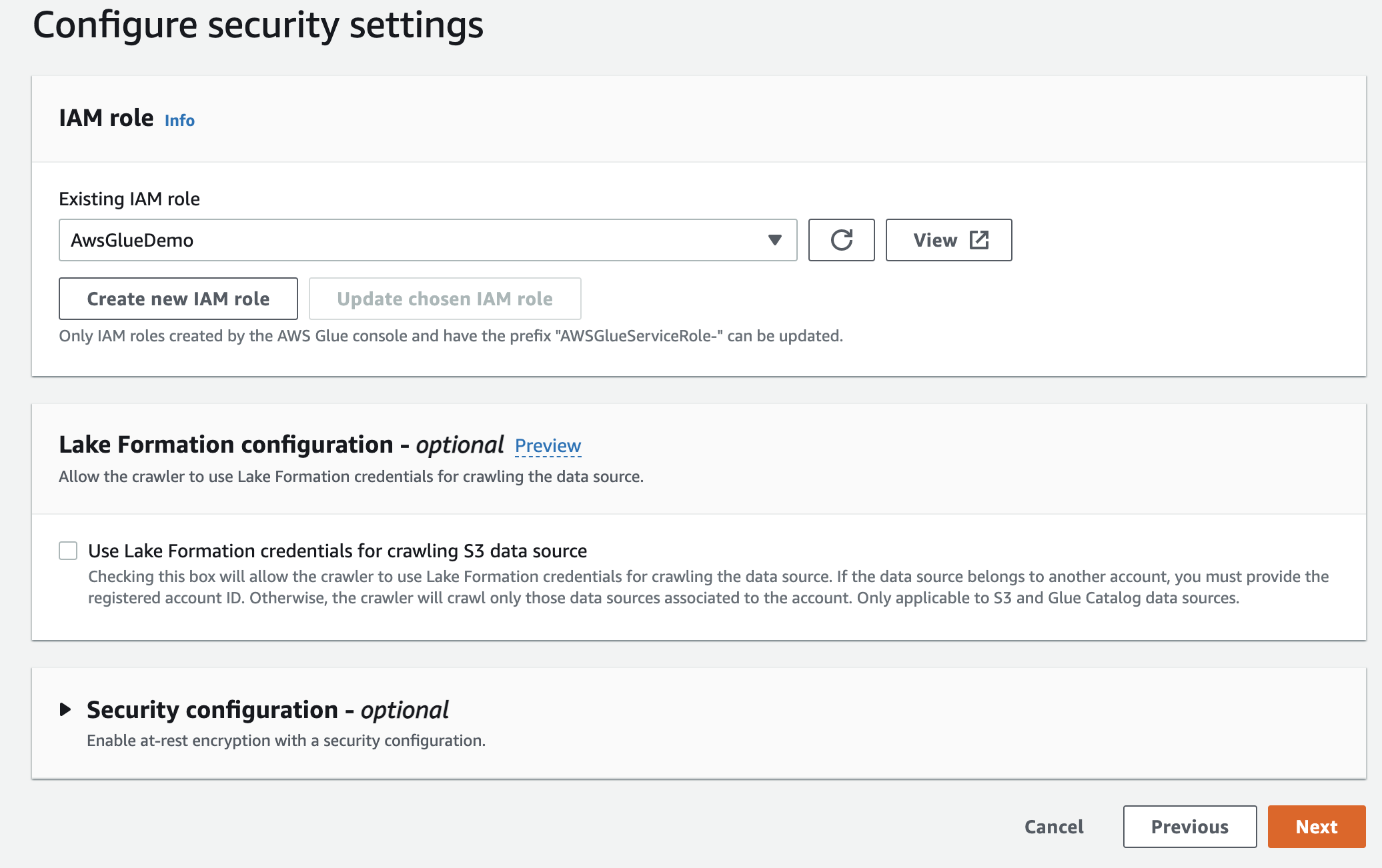
Lastly, within the output, choose gluedb you created.
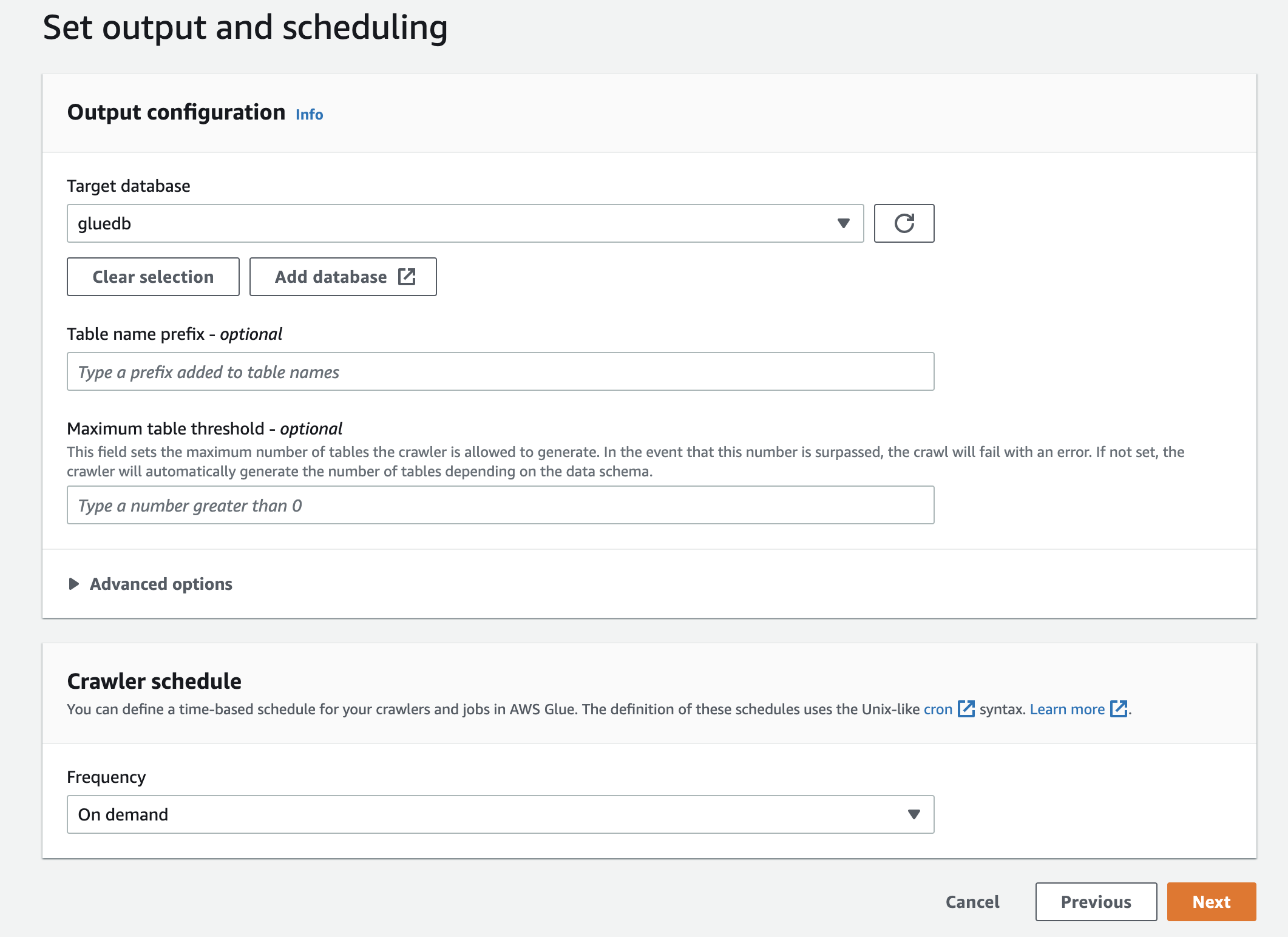
Overview all of the settings and create the crawler.
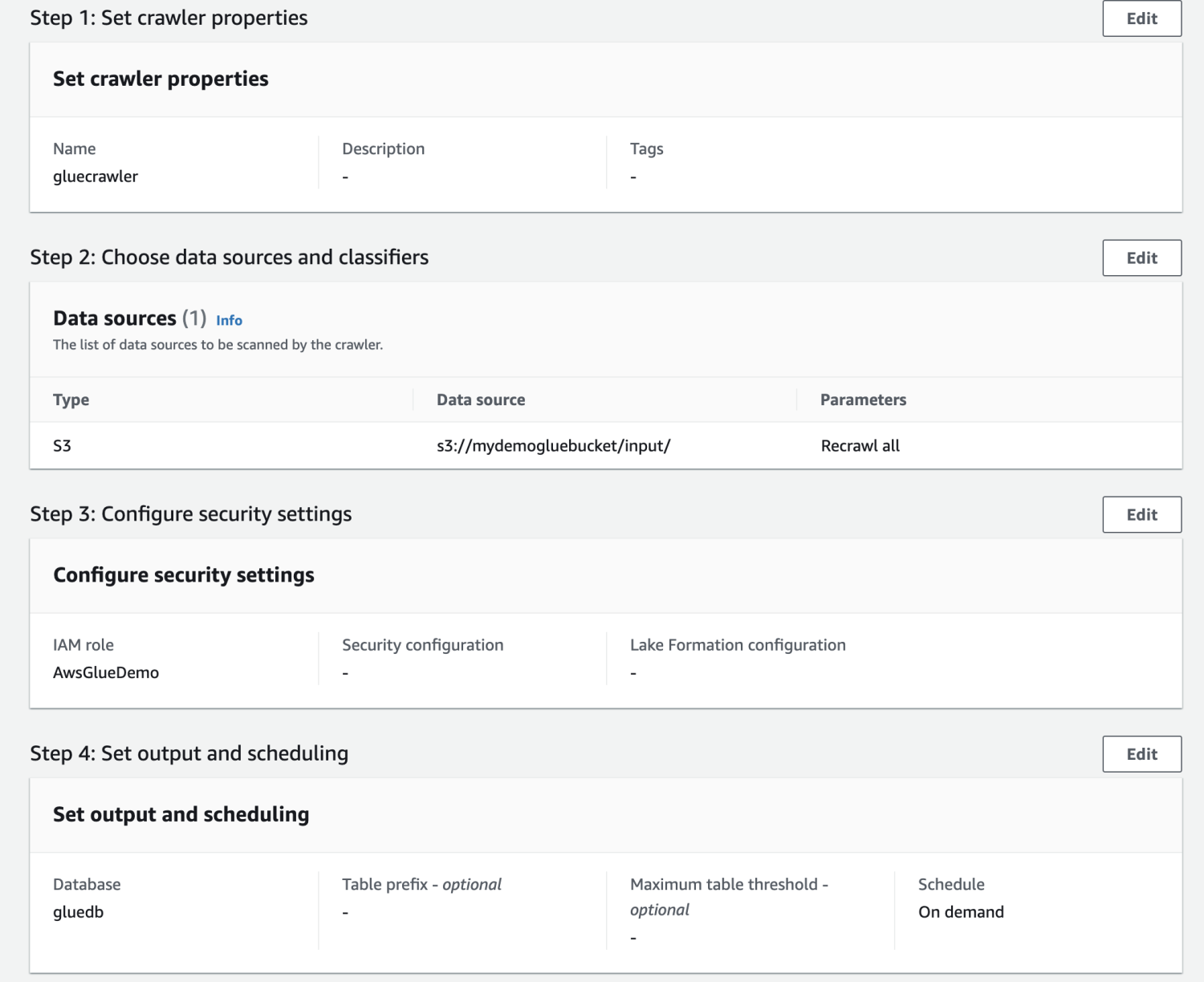
As soon as the crawler is created, choose it and click on on Run. After a while, you’re going to get the standing prepared.
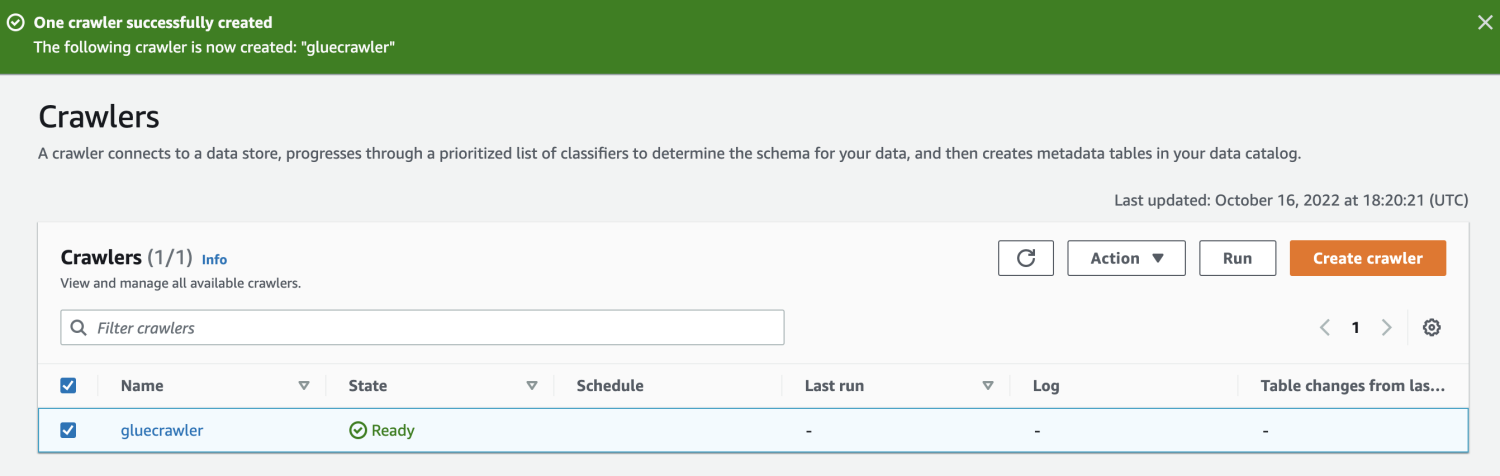
By operating the crawler, the database will get a desk with all the info from the CSV file.
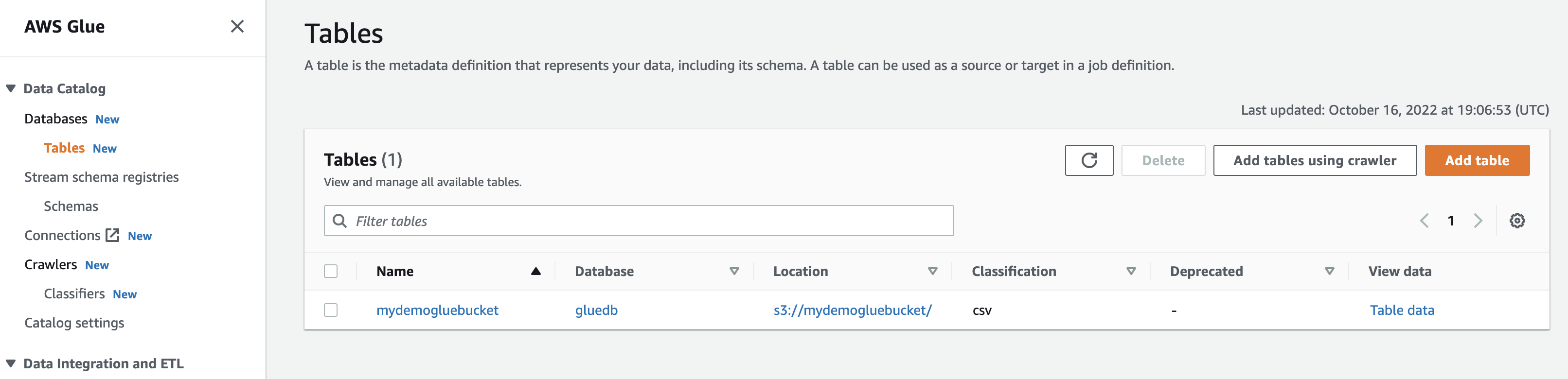
If you click on on view knowledge, you’ll be taken to Amazon Athena (question editor). If you run the question, you possibly can see the desk knowledge.
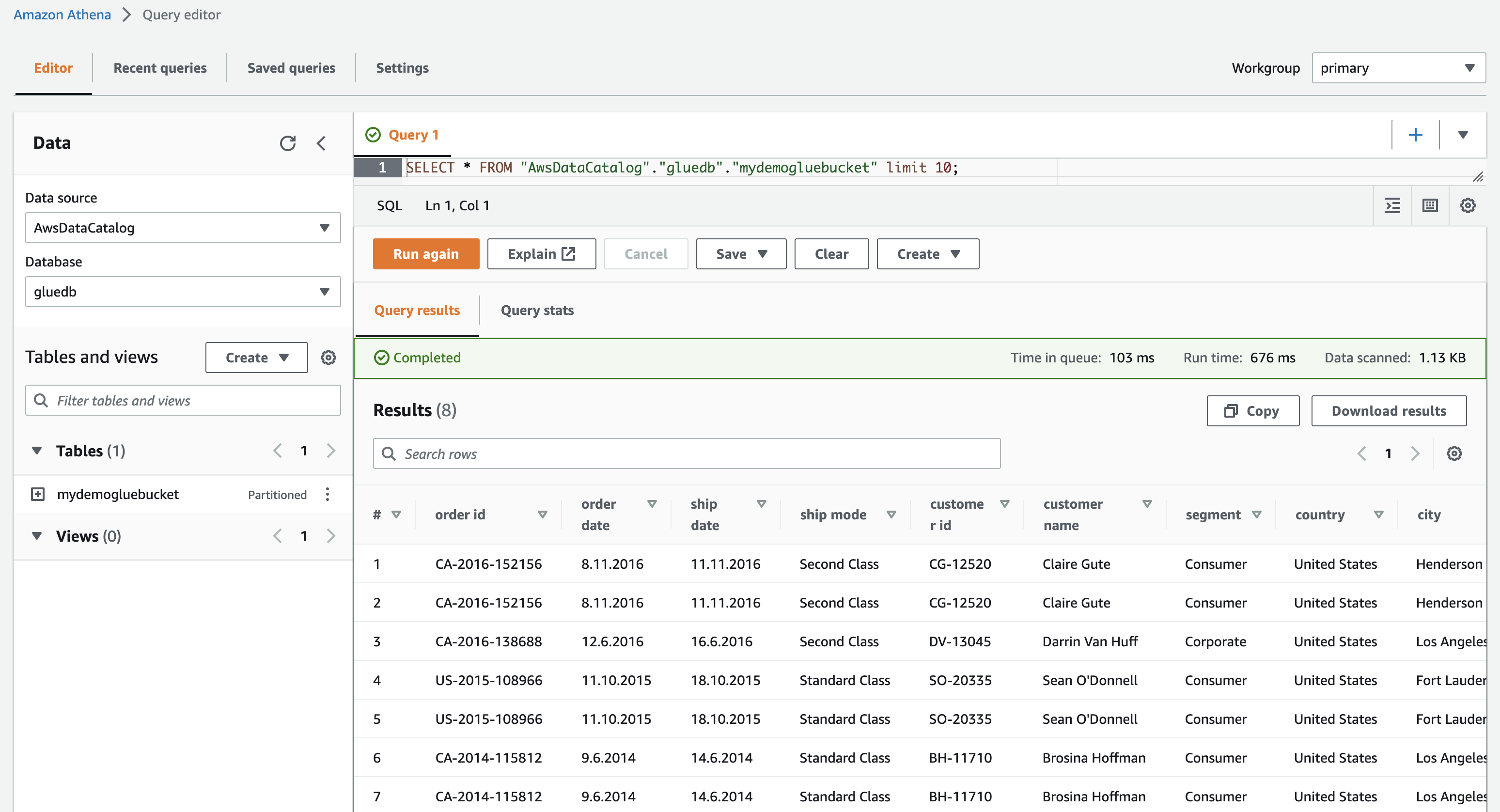
Now you possibly can efficiently use this AWS Glue crawler in any ETL job.
What’s AWS Glue Databrew?
AWS Glue DataBrew permits customers to normalize and clear up knowledge with out writing any code. DataBrew can cut back the time required to arrange knowledge for machine studying and analytics by as a lot as 80 p.c in comparison with custom-developed knowledge preparation.
There are over 250 pre-made knowledge transformations that can be utilized to automate knowledge preparation duties comparable to filtering out anomalies, correcting invalid values, and changing knowledge into customary codecs.
DataBrew makes it simpler for knowledge scientists, enterprise analysts, and engineers to collaborate on extracting insights from uncooked knowledge. DataBrew is serverless, so that you don’t must handle infrastructure or create clusters to discover and rework terabytes price of uncooked knowledge.
DataBrew Options For Enterprises
Visualized Knowledge Preparation
DataBrew is a special approach to view knowledge which can be usually seen in columnar databases as alphanumeric numbers. DataBrew visualizes all loaded knowledge sources that will help you perceive the info relationships and hierarchy.
250+ Knowledge Preparation Automations
Knowledge scientists are anticipated to comply with a wide range of repeatable, remoted workflows as a part of their job. These workflows and processes have been modeled by AWS as language and data-agnostic module modules. This library consists of actions that can be utilized by finish customers.
Knowledge Lineage
Much like audit logs which can be used to trace buyer exercise in an IT community’s IT community, knowledge lineage lets you observe the info transformation actions inside AWS DataBrew. This info consists of the info supply, the transformations utilized, and the info output, together with the goal location.
Knowledge Mapping
Databrew lets you discover matching fields in two knowledge sources. As soon as matching fields have been recognized, they are often loaded right into a schema.
AWS Glue DataBrew: Advantages
Beneath are the options of AWS Glue DataBrew:
- Decrease Barrier to Entry for Knowledge Preparation
- Automated Knowledge Profile Era
- Automate 250+ Knowledge Preparation processes
- Clever Prescriptive Ideas
Options to AWS Glue
Airflow

Airflow belongs to the Workflow Supervisor part of a tech stack. It’s an open-source device that helps GitHub stars, GitHub forks, and different options. Airflow lets you create workflows utilizing directed acyclic diagrams (DAGs). Airflow scheduler executes your duties utilizing an array of staff and following the required dependencies.
Matillion

Matillion ETL, an ETL/ELT device, was designed explicitly for cloud databases platforms comparable to Amazon Redshift and Google BigQuery. It’s a contemporary browser-based UI with highly effective push-down ETL/ELT capabilities. You might be up and operating in minutes with a fast setup.
Sew
Sew is an open-source ETL service that connects a number of knowledge sources and replicates knowledge to most popular locations. It’s very straightforward to make use of, as you don’t want any coding data to maneuver knowledge between sources and locations in Sew. It’s straightforward to make use of, has a pleasant GUI, and it’s quick.
Sew doesn’t help you select a pre-made dashboard, not like different ETL instruments. As an alternative, it’s essential to combine your knowledge into the open knowledge warehouses that you choose as a vacation spot. It may be tough to navigate the inventories.
Alteryx

Alteryx is an analytics automation platform that assists with knowledge assortment preparation and mixing. This knowledge can be utilized to hurry up processes and supply enterprise perception. As a result of it’s a drag-and-drop device, you don’t want any programming data. Alteryx is a superb place to go for recommendation and solutions from trade professionals.
Conclusion
So, that was all about AWS Glue, which is a cloud-based resolution that lets you work with ETL pipelines. To sum up, the AWS Glue person interplay course of is comprised of three phases. To create an information catalog, you first use knowledge crawlers. Subsequent, you create the ETL code required by the AWS knowledge pipeline. Lastly, the ETL schedule is then created. I hope this weblog gave you overview of Amazon Glue.
You may additionally discover one of the best tricks to safe AWS S3 storage.