

Als massive data-analyse nieuw voor je is, staan de vele Apache-tools misschien op je radar; Het grote aantal verschillende hulpmiddelen kan echter verwarrend en soms overweldigend zijn.
Dit bericht zal deze verwarring oplossen en uitleggen wat Apache Hive en Impala zijn en wat hen van elkaar onderscheidt!
Apache-bijenkorf
Apache Hive is een SQL-gegevenstoegangsinterface voor het Apache Hadoop-platform. Met Hive kunt u gegevens opvragen, aggregeren en analyseren met behulp van SQL-syntaxis.
Er wordt een leestoegangsschema gebruikt voor gegevens in het HDFS-bestandssysteem, waardoor u gegevens kunt behandelen zoals bij een gewone tabel of relationeel DBMS. HiveQL-query’s worden vertaald in Java-code voor MapReduce-taken.

Hive-query’s worden geschreven in de HiveQL-querytaal, die is gebaseerd op de SQL-taal, maar geen volledige ondersteuning biedt voor de SQL-92-standaard.
Met deze taal kunnen programmeurs hun question’s echter gebruiken wanneer het lastig of inefficiënt is om HiveQL-functies te gebruiken. HiveQL kan worden uitgebreid met door de gebruiker gedefinieerde scalaire functies (UDF’s), aggregaties (UDAF-codes) en tabelfuncties (UDTF’s).
Hoe werkt Apache Hive
Apache Hive vertaalt programma’s die zijn geschreven in de HiveQL-taal (dicht bij SQL) naar een of meer MapReduce-, Apache Tez- of Apache Spark-taken. Dit zijn drie uitvoeringsmotoren die op Hadoop kunnen worden gelanceerd. Vervolgens organiseert Apache Hive de gegevens in een array voor het Hadoop Distributed File System (HDFS)-bestand om de taken op een cluster uit te voeren en een antwoord te produceren.
Apache Hive-tabellen zijn vergelijkbaar met relationele databases, en gegevenseenheden zijn georganiseerd van de meest significante eenheid tot de meest gedetailleerde. Databases zijn arrays die zijn samengesteld uit partities, die weer kunnen worden opgesplitst in ‘buckets’.

De gegevens zijn toegankelijk through HiveQL. Binnen elke database zijn de gegevens genummerd en komt elke tabel overeen met een HDFS-directory.
Er zijn meerdere interfaces beschikbaar binnen de Apache Hive-architectuur, zoals een webinterface, CLI of externe shoppers.
Met de “Apache Hive Thrift”-server kunnen externe shoppers opdrachten en verzoeken indienen bij Apache Hive met behulp van verschillende programmeertalen. De centrale listing van Apache Hive is een “metastore” die alle informatie bevat.
De motor die Hive laat werken, wordt ‘de driver’ genoemd. Het bundelt een compiler en een optimizer om het optimale uitvoeringsplan te bepalen.
Tenslotte wordt de beveiliging verzorgd door Hadoop. Het vertrouwt daarom op Kerberos voor wederzijdse authenticatie tussen de consumer en de server. De toestemming voor nieuw gemaakte bestanden in Apache Hive wordt bepaald door HDFS, waardoor gebruikers-, groeps- of anderszins autorisatie mogelijk is.
Kenmerken van Hive
- Ondersteunt de computerengine van zowel Hadoop als Spark
- Maakt gebruik van HDFS en werkt als een datawarehouse.
- Maakt gebruik van MapReduce en ondersteunt ETL
- Dankzij HDFS heeft het een fouttolerantie die vergelijkbaar is met Hadoop
Apache Hive: voordelen
Apache Hive is een ideale oplossing voor queries en data-analyse. Het maakt het mogelijk om kwalitatieve inzichten te verkrijgen, wat een concurrentievoordeel oplevert en het inspelen op de marktvraag vergemakkelijkt.
Een van de belangrijkste voordelen van Apache Hive is het gebruiksgemak dat verband houdt met de “SQL-vriendelijke” taal. Bovendien versnelt het de initiële invoer van gegevens, omdat de gegevens niet hoeven te worden gelezen of genummerd vanaf een schijf in het interne databaseformaat.
Wetende dat de gegevens worden opgeslagen in HDFS, is het mogelijk om grote datasets van wel honderden petabytes aan gegevens op Apache Hive op te slaan. Deze oplossing is veel schaalbaarder dan een traditionele database. Wetende dat het een cloudservice is, stelt Apache Hive gebruikers in staat snel virtuele servers te starten op foundation van schommelingen in de werklast (dwz taken).
Beveiliging is ook een facet waarop Hive beter presteert, omdat het in geval van een probleem herstelkritieke workloads kan repliceren. Ten slotte is de werkcapaciteit ongeëvenaard, aangezien deze tot 100.000 verzoeken per uur kan uitvoeren.
Apache Impala
Apache Impala is een enorm parallelle SQL-query-engine voor de interactieve uitvoering van SQL-query’s op gegevens die zijn opgeslagen in Apache Hadoop, geschreven in C++ en gedistribueerd onder de Apache 2.0-licentie.
Impala wordt ook wel een MPP-engine (Massively Parallel Processing), een gedistribueerd DBMS en zelfs een SQL-on-Hadoop-stackdatabase genoemd.
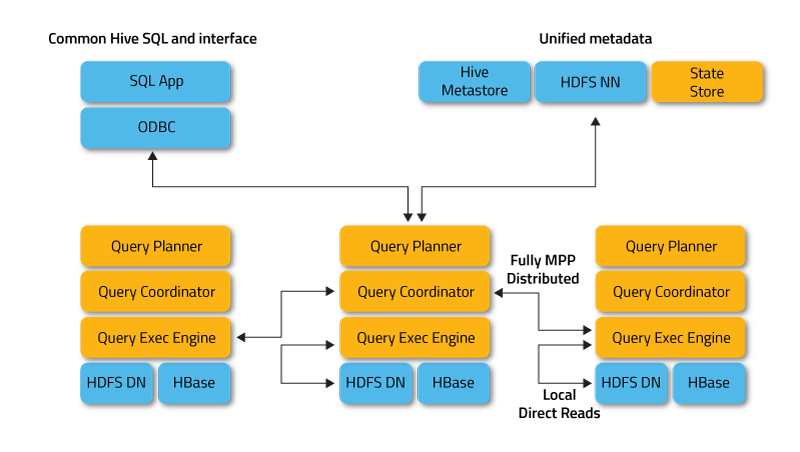
Impala werkt in de gedistribueerde modus, waarbij procesinstanties op verschillende clusterknooppunten worden uitgevoerd en klantverzoeken ontvangen, plannen en coördineren. In dit geval is parallelle uitvoering van fragmenten van de SQL-query mogelijk.
Shoppers zijn gebruikers en applicaties die SQL-query’s verzenden op gegevens die zijn opgeslagen in Apache Hadoop (HBase en HDFS) of Amazon S3. Interactie met Impala vindt plaats through de HUE-webinterface (Hadoop Consumer Expertise), ODBC, JDBC en de opdrachtregelshell van Impala Shell.
Impala is infrastructureel afhankelijk van een andere populaire SQL-on-Hadoop-tool, Apache Hive, die gebruik maakt van zijn metadata-opslag. Met title de Hive Metastore informeert Impala over de beschikbaarheid en structuur van de databases.
Bij het maken, wijzigen en verwijderen van schemaobjecten of het laden van gegevens in tabellen through SQL-instructies, worden de bijbehorende metagegevenswijzigingen automatisch doorgegeven aan alle Impala-knooppunten met behulp van een gespecialiseerde directoryservice.
De belangrijkste componenten van Impala zijn de volgende uitvoerbare bestanden:
- Impalad of Impala daemon is een systeemservice die question’s plant en uitvoert op HDFS-, HBase- en Amazon S3-gegevens. Op elk clusterknooppunt wordt één impalad-proces uitgevoerd.
- Statestore is een naamgevingsservice die de locatie en standing van alle Impalad-instanties in het cluster bijhoudt. Op elk knooppunt en op de hoofdserver (Title Node) wordt één exemplaar van deze systeemservice uitgevoerd.
- Catalog is een metadata-coördinatieservice die wijzigingen van Impala DDL- en DML-instructies doorgeeft aan alle betrokken Impala-knooppunten, zodat nieuwe tabellen of nieuw geladen gegevens onmiddellijk zichtbaar zijn voor elk knooppunt in het cluster. Het wordt aanbevolen dat één exemplaar van Catalog wordt uitgevoerd op dezelfde clusterhost als de Statestored-daemon.
Hoe werkt Apache Impala
Impala gebruikt, web als Apache Hive, een vergelijkbare declaratieve querytaal, Hive Question Language (HiveQL), een subset van SQL92, in plaats van SQL.
De daadwerkelijke uitvoering van het verzoek in Impala is als volgt:
De clienttoepassing verzendt een SQL-query door verbinding te maken met een willekeurige impalad through gestandaardiseerde ODBC- of JDBC-stuurprogramma-interfaces. De aangesloten impalade wordt de coördinator van de huidige aanvraag.
De SQL-query wordt geanalyseerd om de taken voor de impalad-instanties in het cluster te bepalen; Vervolgens wordt het optimale query-uitvoeringsplan opgesteld.
Impalad heeft rechtstreeks toegang tot HDFS en HBase met behulp van lokale exemplaren van systeemservices om gegevens te leveren. In tegenstelling tot Apache Hive bespaart een dergelijke directe interactie de uitvoeringstijd van question’s aanzienlijk, omdat tussenresultaten niet worden opgeslagen.
Als reactie hierop retourneert elke daemon gegevens naar de coördinerende impalad en stuurt de resultaten terug naar de consumer.
Kenmerken van Impala
- Ondersteuning voor realtime verwerking in het geheugen
- SQL-vriendelijk
- Ondersteunt opslagsystemen zoals HDFS, Apache HBase en Amazon S3
- Ondersteunt integratie met BI-tools zoals Pentaho en Tableau
- Maakt gebruik van HiveQL-syntaxis
Apache Impala: voordelen
Impala vermijdt mogelijke opstartoverhead omdat alle systeemdaemon-processen direct tijdens het opstarten worden gestart. Het bespaart aanzienlijk de uitvoeringstijd van question’s. Een further verhoging van de snelheid van Impala komt doordat deze SQL-tool voor Hadoop, in tegenstelling tot Hive, geen tussenresultaten opslaat en rechtstreeks toegang heeft tot HDFS of HBase.
Bovendien genereert Impala programmacode tijdens runtime en niet tijdens het compileren, zoals Hive doet. Een neveneffect van de hoge snelheidsprestaties van Impala is echter een verminderde betrouwbaarheid.
Met title als het gegevensknooppunt uitvalt tijdens de uitvoering van een SQL-query, wordt de Impala-instantie opnieuw opgestart en blijft Hive verbinding houden met de gegevensbron, waardoor fouttolerantie wordt geboden.
Andere voordelen van Impala zijn onder meer ingebouwde ondersteuning voor een veilig netwerkverificatieprotocol Kerberos, prioritering en de mogelijkheid om de wachtrij met verzoeken te beheren en ondersteuning voor populaire Large Information-formaten zoals LZO, Avro, RCFile, Parquet en Sequence.
Hive versus Impala: overeenkomsten
Hive en Impala worden free of charge gedistribueerd onder de Apache Software program Basis-licentie en verwijzen naar SQL-tools voor het werken met gegevens die zijn opgeslagen in een Hadoop-cluster. Daarnaast gebruiken ze ook het gedistribueerde HDFS-bestandssysteem.
Impala en Hive implementeren verschillende taken met een gemeenschappelijke focus op SQL-verwerking van massive information opgeslagen in een Apache Hadoop-cluster. Impala biedt een SQL-achtige interface waarmee u Hive-tabellen kunt lezen en schrijven, waardoor gegevensuitwisseling eenvoudig mogelijk is.
Tegelijkertijd maakt Impala SQL-bewerkingen op Hadoop vrij snel en efficiënt, waardoor het gebruik van dit DBMS in Large Information-analyseonderzoeksprojecten mogelijk wordt. Waar mogelijk werkt Impala met een bestaande Apache Hive-infrastructuur die al wordt gebruikt om langlopende SQL-batchquery’s uit te voeren.
Bovendien slaat Impala zijn tabeldefinities op in een metastore, een traditionele MySQL- of PostgreSQL-database, dat wil zeggen op dezelfde plaats waar Hive vergelijkbare gegevens opslaat. Hiermee heeft Impala toegang tot Hive-tabellen zolang alle kolommen de door Impala ondersteunde gegevenstypen, bestandsindelingen en compressiecodecs gebruiken.
Hive versus Impala: verschillen

Programmeertaal
Hive is geschreven in Java, terwijl Impala is geschreven in C++. Impala gebruikt echter ook enkele op Java gebaseerde Hive UDF’s.
Gebruiksgevallen
Information Engineers gebruiken Hive in ETL-processen (Extract, Remodel, Load), bijvoorbeeld voor langlopende batchtaken op grote datasets, bijvoorbeeld in reisaggregators en luchthaveninformatiesystemen. Impala is op zijn beurt vooral bedoeld voor analisten en datawetenschappers en wordt vooral gebruikt bij taken als enterprise intelligence.
Prestatie
Impala voert SQL-query’s in realtime uit, terwijl Hive wordt gekenmerkt door een lage gegevensverwerkingssnelheid. Met eenvoudige SQL-query’s kan Impala 6-69 keer sneller draaien dan Hive. Hive verwerkt complexe question’s echter beter.
Latentie/doorvoer
De doorvoer van Hive is aanzienlijk hoger dan die van Impala. De LLAP-functie (Dwell Lengthy and Course of), die het cachen van question’s in het geheugen mogelijk maakt, levert Hive goede prestaties op laag niveau.
LLAP omvat langetermijnsysteemservices (daemons), waarmee u rechtstreeks kunt communiceren met HDFS-dataknooppunten en de nauw geïntegreerde DAG-querystructuur (Directed acyclic graph) kunt vervangen – een grafiekmodel dat actief wordt gebruikt in Large Information-computing.
Fouttolerantie
Hive is een fouttolerant systeem dat alle tussenresultaten behoudt. Het heeft ook een positieve invloed op de schaalbaarheid, maar leidt tot een afname van de gegevensverwerkingssnelheid. Op zijn beurt kan Impala geen fouttolerant platform worden genoemd omdat het meer geheugengebonden is.
Codeconversie
Hive genereert query-expressies tijdens het compileren, terwijl Impala deze tijdens runtime genereert. Hive wordt gekenmerkt door een ‘koude begin’-probleem de eerste keer dat de applicatie wordt gestart; zoekopdrachten worden langzaam geconverteerd omdat er een verbinding met de gegevensbron tot stand moet worden gebracht.
Impala heeft dit soort opstartkosten niet. De noodzakelijke systeemdiensten (daemons) voor het verwerken van SQL-query’s worden tijdens het opstarten gestart, wat het werk versnelt.
Ondersteuning voor opslag
Impala ondersteunt de formaten LZO, Avro en Parquet, terwijl Hive werkt met platte tekst en ORC. Beide ondersteunen echter de indelingen RCFIle en Sequence.
| Apache-bijenkorf | Apache Impala | |
| Taal | Java | C++ |
| Gebruiksscenario’s | Information-engineering | Analyse en analyse |
| Prestatie | Hoog voor eenvoudige zoekopdrachten | Relatief laag |
| Latentie | Meer latentie door caching | Minder latent |
| Fouttolerantie | Verdraagzamer dankzij MapReduce | Minder tolerant vanwege MPP |
| Conversie | Langzaam door koude begin | Snellere conversie |
| Ondersteuning voor opslag | Platte tekst en ORC | LZO, Avro, Parket |
laatste woorden
Hive en Impala concurreren niet, maar vullen elkaar effectief aan. Ook al zijn er aanzienlijke verschillen tussen de twee, er is ook veel gemeen en de keuze voor de een boven de ander hangt af van de gegevens en de specifieke vereisten van het venture.
U kunt ook rechtstreekse vergelijkingen tussen Hadoop en Spark onderzoeken.
.